What You Should Know About B-Trees on Disk (But Probably Don't)
9 min read
While reading Database Internals, I realized that I had always pictured B-Trees as purely in-memory data structures. But in reality, most production databases store B-Trees on disk, not in RAM.
It might seem simple, but pointer management works very differently on disk than in memory. That insight sparked my curiosity, so I dug deeper into how B-Trees are actually laid out on disk. In this article, I'll walk you through the core concepts and general strategies most disk-based B-Tree implementations follow. While specifics vary across databases, the foundational ideas remain widely shared.
If you like to deep-dive into database internals, then you are going to love this. Let's begin.
General principles
Before diving into B-Trees, let's zoom out and look at how databases store data on disk.
Most databases use a set of structured files, typically divided into two broad types: data files, which store the actual records, and index files, which help locate those records efficiently. While formats can vary, these files usually follow a common high-level structure, which is shown in the image given below:
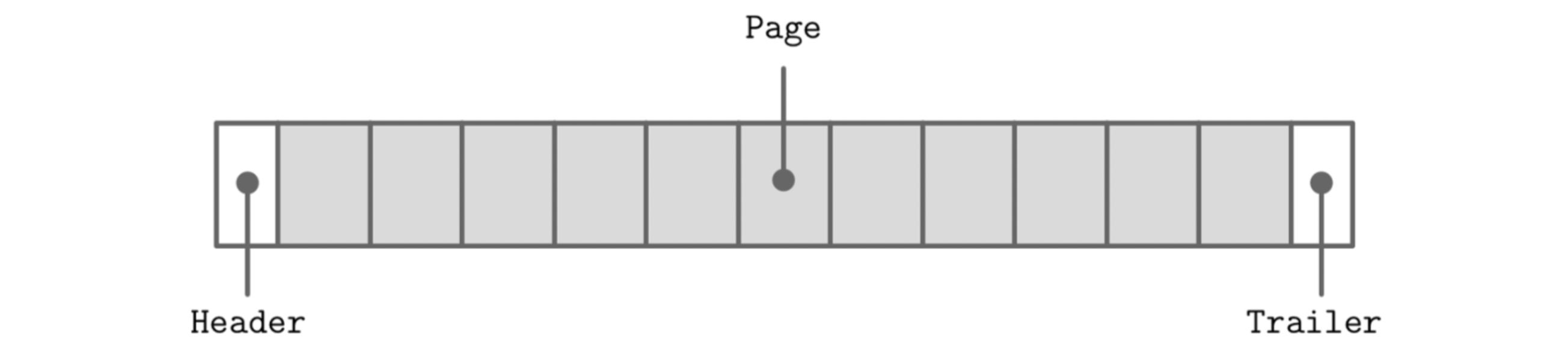
- Header: A fixed-size section at the beginning of the file that contains metadata, such as file format version, page size, and sometimes checksums.
- Pages: The bulk of the file consists of fixed-size pages (usually 4 KB to 16 KB) that store actual data or index entries. Each page may follow its own internal layout.
- Trailer: Some formats include a trailer at the end of the file, which may store checksums, footers, or other metadata used for integrity or versioning.
Now that we've covered the outer structure, let's zoom in on the page itself, the unit where the interesting stuff happens.
Page structure
As we just saw, data is stored in fixed-size units called pages, typically 4 to 16 KB each. In most database systems, each B-Tree node is stored within a single page, so the terms node and page are often used interchangeably in this context.
Before diving into how these pages are physically laid out, here's a quick refresher on the logical structure of a B-Tree node, based on the original B-Tree design from the academic literature:
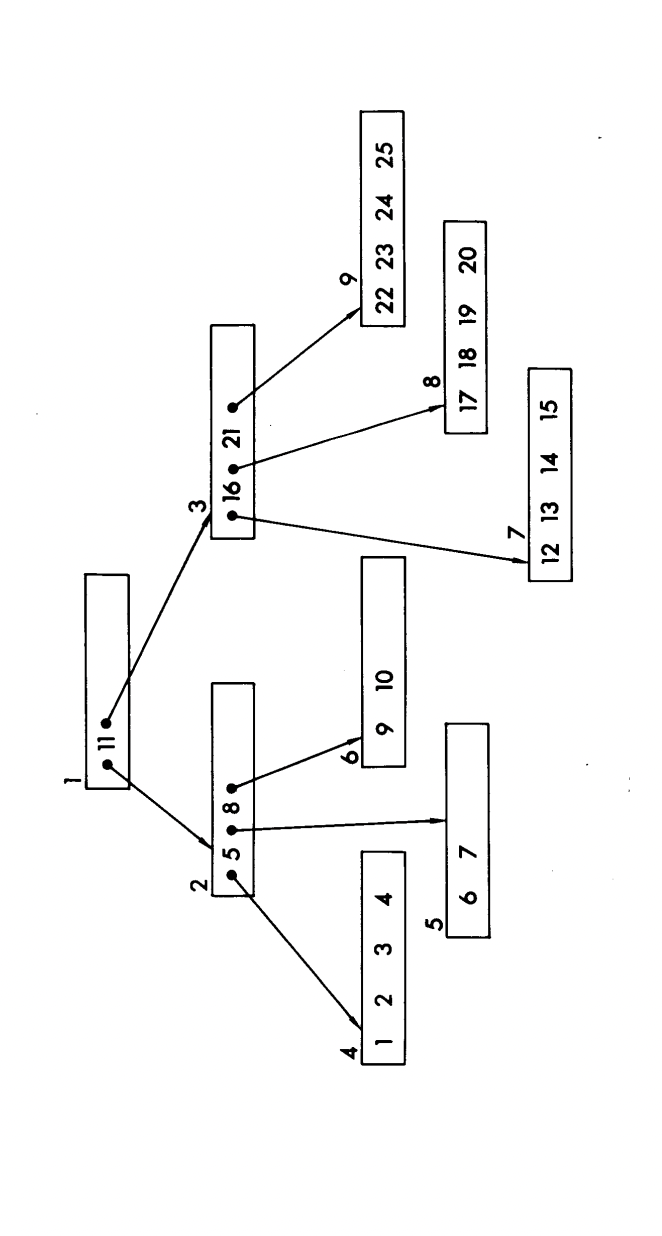
In this structure, each node is essentially a list of triplets: Key (K), Value (V), and Pointer (P) to child pages. The key acts as a separator, the value holds the associated data, and the pointer links to a child page. The same is shown in the image given below at the page level:

Note that this is a classic B-Tree, not a B+ Tree, which means the data records can live in internal nodes, not just the leaves.
While conceptually simple, this layout has two big downsides:
- Insertions in the middle of the node require shifting many elements to maintain order.
- It struggles with variable-sized records, since everything is tightly packed with no room to grow or move flexibly.
Enter, slotted pages
The B-Tree layout we saw earlier works fine for fixed-size keys and values, but it struggles with variable-sized records, which are common in real databases. The core issue is that when record sizes vary, it becomes difficult to predict how many will fit in a page. Overestimating wastes space (internal fragmentation); underestimating leads to frequent splits or overflows.
Some databases try to clean up fragmented pages periodically using background processes (similar to garbage collection). But compacting a page can become tricky if other pages hold direct references to record offsets, as this would require updating those references too, which could be an expensive operation.
To make variable-sized records easier to manage, many modern databases adopt a layout called the slotted page. Here's what that looks like conceptually:
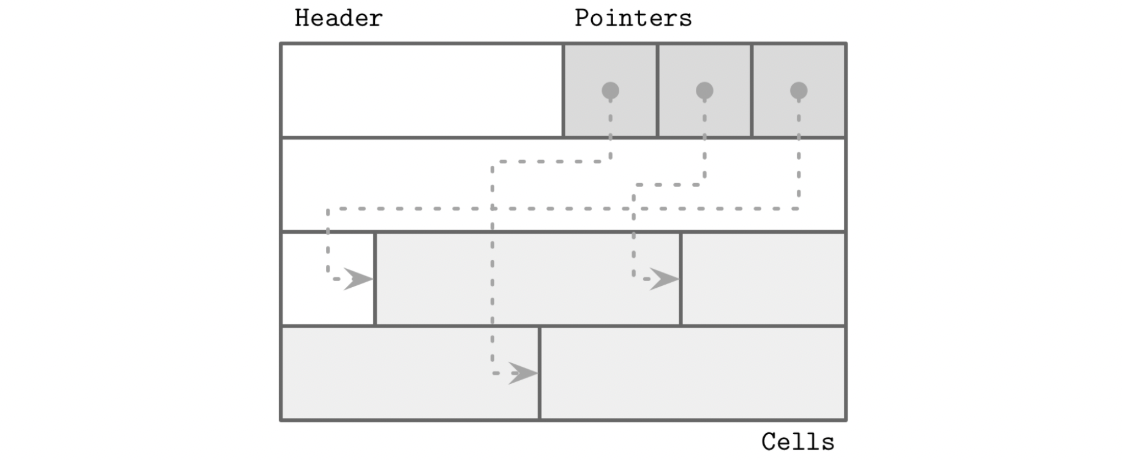
In this structure, we organise the page into the following components:
- Page Header: A fixed-size section at the top that stores metadata about the page, like the number of records, space usage, etc.
- Cells (Records): The actual data entries, which may include key-value pairs, pointers, or other payloads.
- Slot Directory (Pointers): A list of offsets pointing to the location of each cell within the page.
Pointers and cells are split into two different regions, at the extreme ends, which makes the cells grow from one end of the page, while pointers grow from the other. This also means that we only need to preserve the order of pointers in this page and not the cells themselves to be able to do an efficient lookup. Deleting a record just means removing or nullifying its pointer. The actual cell can be cleaned up later.
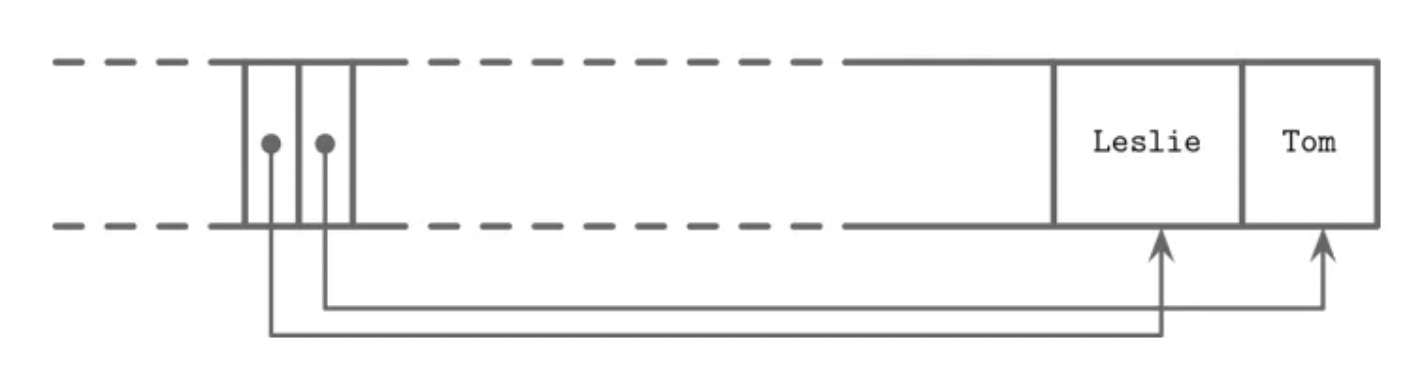
Let's see a quick example to understand this better. Suppose we have a page storing two variable-sized strings -- "Leslie" and "Tom" -- inserted in sorted order. Using a slotted page layout, this could be visualized as shown in the image below:
Now let's say we insert another name: "Ron". The actual record for "Ron" is placed in the free space region between the pointer table and the existing cells. This might make the physical layout of cells appear unordered as shown in the image given below:
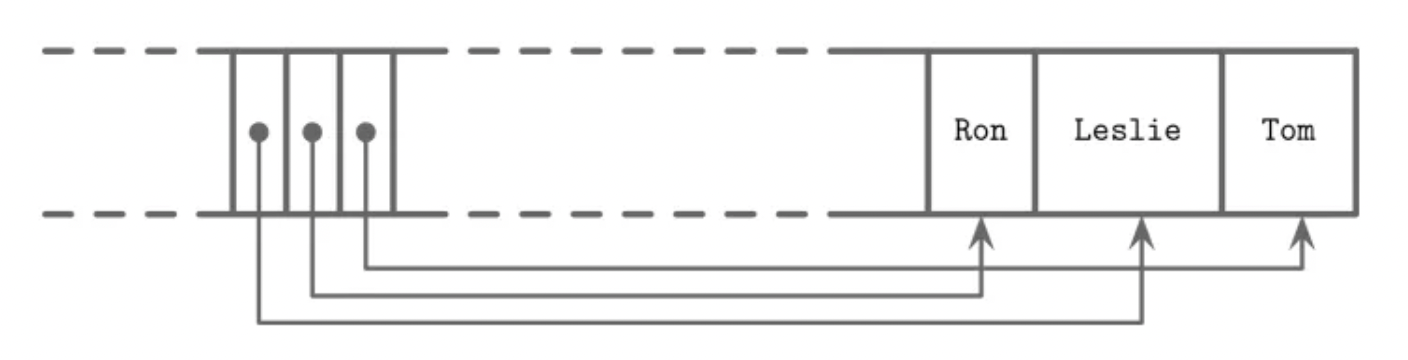
But here's the key: the pointers are always kept sorted. So even if the records are scattered across the page, binary search over the sorted pointers still works efficiently.
Recollecting wasted space
In real-world workloads, data isn't just read and written; it's also frequently deleted. Consider a page that once held several records. Over time, some of those records may be removed, leaving behind gaps in the cell region. This situation could be visualised in the image below:
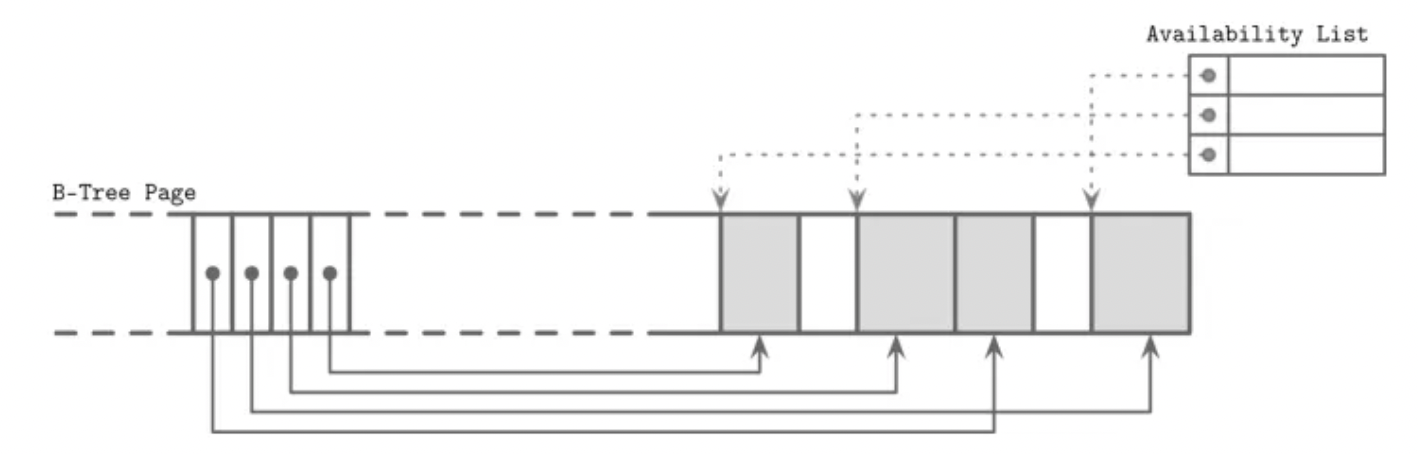
These gaps aren't wasted; the database tracks them using a structure called an availability list, which is a list of free spaces within the page. When new data needs to be inserted, the system consults this list to find a suitable spot instead of always appending at the end.
The strategy used to pick a spot can vary, but at a high level, it's often something simple like first-fit (the first available space that fits the record) or best-fit (the smallest available space that fits the record without wasting much).
Cell layout
In this section, we will see how the cells are laid out in a B+-Tree page. In B+-Tree pages, there are broadly two types of cells:
- Key cells: Used in internal (non-leaf) pages. They store a separator key and a pointer (typically a page ID) to the child page that falls between two neighboring keys.
- Key-value cells: Used in leaf pages. These store the key along with the associated data record (the value).
The layout for the key cells looks like this:

Here:
key_sizehelps determine how many bytes the key spans.page_idpoints to the child page.keyis the actual separator key used for navigation.
By grouping fixed-size fields at the beginning, databases can parse these cells more efficiently before reading the variable-length key.
Now, let's look at a key-value cell, which typically appears in leaf pages. Its layout is as follows:

Here:
key_sizetells us the length of the key.value_sizespecifies the length of the data record (value).keyis the actual key used for lookup.data_recordis the value associated with the key.
Just like in key cells, the fixed-size fields (key_size and value_size) come first, followed by the variable-length fields. This design allows efficient parsing and scanning, even with variable-sized keys and values.
Ending notes
We started with the basics of B-Trees and looked at how things change when they're stored on disk instead of in memory. From slotted pages to availability lists and how cells are laid out, there's a lot more going on than it might seem at first.
Thank you for reading.
I regularly read a wide range of technical books and share my learnings here, whether it's database internals, system design, or just clever engineering ideas. Feel free to explore the rest of the blogs if that sounds interesting to you.
Thank you for reading.
Happy coding!