Everyone Talks About B+ Trees, But Do You Know the Bw-Tree?
7 min read
B+ Trees have powered databases for decades, but they weren’t built with today’s hardware in mind. Enter the Bw-Tree, a modern, latch-free alternative designed for high-concurrency environments like SSDs and in-memory systems. While it may look similar to a B+ Tree at first glance, its underlying mechanics are fundamentally different.
If you’re curious about how Bw-Trees improve write performance, reduce contention, and exploit modern CPU architectures, this post breaks it down with examples and visuals. Let’s dive in.
What is a Bw-Tree?
The Bw-Tree (short for “Buzz Word Tree”) is a lock-free, high-performance variant of the B+ Tree. It was developed to avoid the pitfalls of traditional tree structures on modern multi-core systems and SSDs. Conceptually, it’s still a balanced tree, but the way it handles updates, concurrency, and memory is completely reimagined.
Let’s walk through some of the key components that make it different.
BTW, if you want to know more about B+ Trees on disk, then read this article of mine.
The mapping table: Decoupling pointers from data
Unlike a B+ Tree, which uses direct pointers between nodes, a Bw-Tree introduces an indirection layer through a mapping table.
- Each node is identified by a logical ID.
- The mapping table maps these IDs to physical memory addresses.
- When a node moves, you only update the mapping table, not the tree structure.
- This update happens through CAS operations, which are atomic CPU instructions that let you safely replace memory content without locks. Because of this, Bw-Trees can update mappings without blocking other threads.
It can be visualised in the image given below:
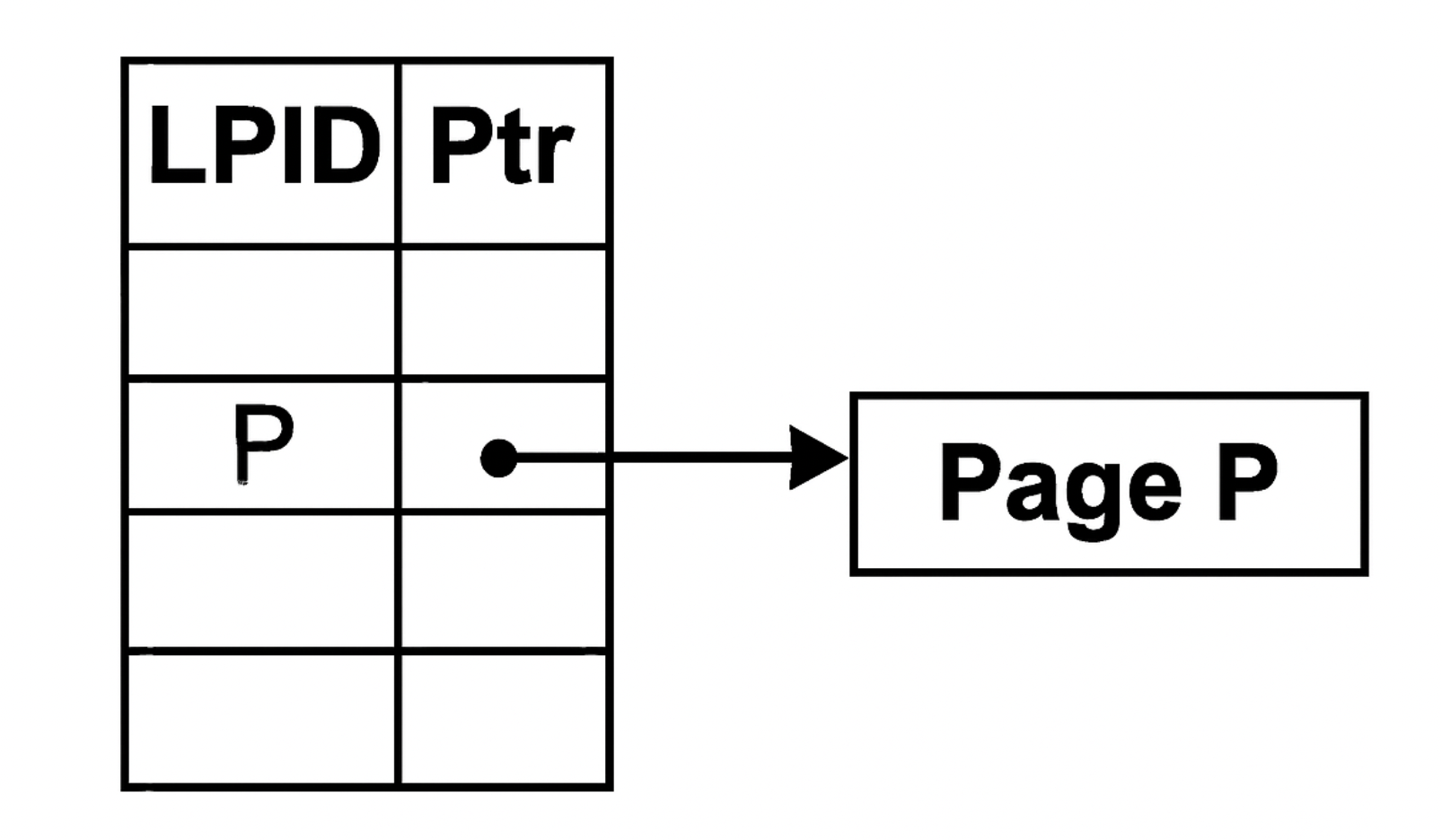
The advantage of a mapping table is that you avoid the need to update multiple pointers, eliminate lock contention, and keep all node access indirect, making the structure safer and faster under concurrency.
Delta records: Log-structured updates on top of data
Rather than modifying nodes directly, Bw-Trees append delta records for each update (insert, delete, or modify). These records are linked in a chain above the original node (called the base record).
For example, suppose you insert key 42. Instead of modifying the leaf node directly, a delta record like Insert(42) is created. This delta is prepended to the node’s delta chain. This entire arrangement looks something like below:
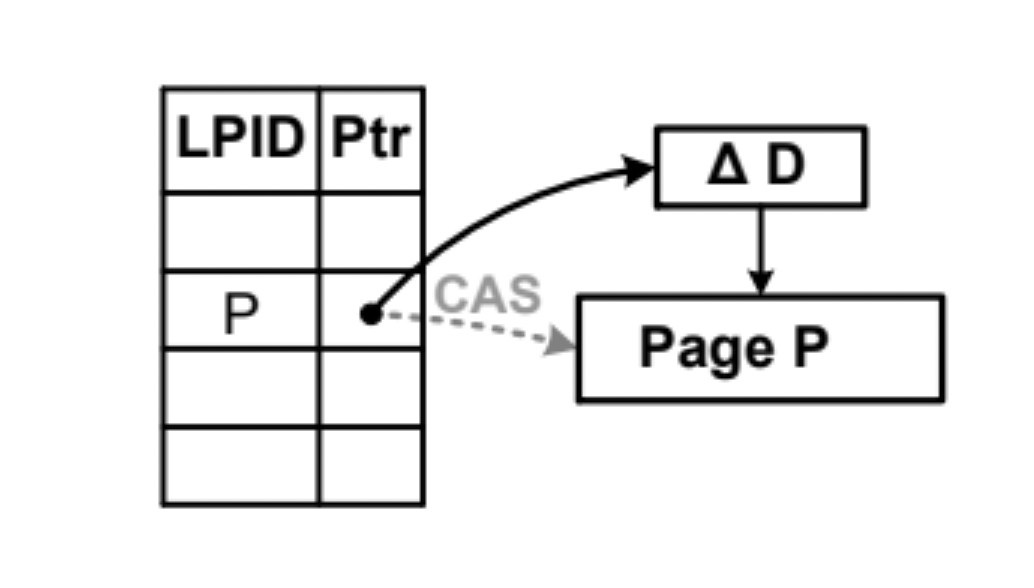
Over time, this creates a stack of changes. When a read is performed, the tree traverses the delta chain and reconstructs the final view of the data.
To keep read performance in check, delta chains are periodically consolidated into a new base record. This process is similar to compaction in log-structured systems, as it rewrites scattered deltas into a single, coherent snapshot. This process is represented in the image given below:
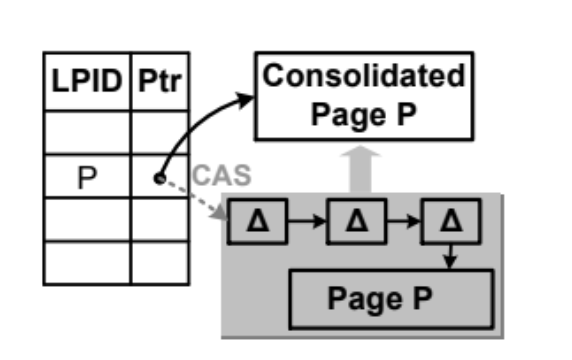
Now that we have understood the high-level working of a Bw-Tree, let’s understand in what terms it is better than a B-Tree in the next section.
How Bw-Trees outperform B+ Trees
Let’s break down the performance gains that Bw-Trees offer over traditional B+ Trees.
No latches, no contention
B+ Trees use latches (locks) to ensure correctness during concurrent access. On multi-core systems, this becomes a bottleneck.
Bw-Trees sidestep this entirely. Since updates go into delta records and existing pages aren’t changed in place, there’s no need to lock them. CAS handles synchronization, enabling lock-free concurrency.
Better CPU cache behavior
Here’s a subtle but important performance issue in B+ Trees:
When multiple threads access and modify shared nodes, CPU cache lines are invalidated across cores (due to the MESI protocol). This leads to frequent cache misses and slow memory reads. Bw-Trees avoid this by treating all nodes as immutable. Updates go into new delta records, which are stored separately. As a result, Bw-Trees experience fewer cache invalidations and maintain better CPU cache locality.
(For a deep dive on this, see my earlier post on CPU cache behavior).
Lower write amplification
In B+ Trees, even a one-byte update means writing the full page back to disk. This leads to high write amplification.
Bw-Trees reduce this in several ways:
- Writes go to small delta records, not full pages.
- These records are buffered in memory.
- When the buffer fills up, delta records are batched and flushed sequentially, amortizing the I/O cost.
This design makes Bw-Trees especially well-suited for SSDs, where sequential writes are much faster than random ones.
Limitations of Bw-Trees
Like any system, Bw-Trees come with trade-offs.
Read path overhead
Delta records speed up writes, but they make reads more expensive. Reconstructing the actual data from a chain of deltas can involve multiple memory/disk lookups and CPU cycles. It is more prominent when chains get long.
Consolidation cost
Periodic delta chain consolidation is necessary for performance and storage efficiency. However, this process is I/O- and CPU-intensive, particularly under write-heavy workloads.
It’s similar to garbage collection, necessary but not free.
CAS retries under contention
CAS is lock-free but not contention-free. If multiple threads try to update the same node ID simultaneously, CAS may fail and require retries. In high-contention scenarios, this can affect throughput.
Ending notes
The world of databases is really fascinating. I learned a lot of new things while learning about the Bw trees. While this post scratches the surface, I highly recommend going deeper if you’re working on high-performance storage systems or enjoy diving into database internals.
Here are some great starting points:
https://www.youtube.com/watch?v=Pr-b9stpAV4&ab_channel=UWDatabaseGroup
https://drive.google.com/file/d/1IMGXQ5exYx5PbiAInPH8tbXRbUclhzyn/view?usp=sharing
I regularly read a wide range of technical books and share my learnings here, whether it's database internals, system design, or just clever engineering ideas. Feel free to explore the rest of the blogs if that sounds interesting to you.
Thank you for reading.
Happy coding!