Lucene's Inverted Index Is Not What You Think It Is
4 min read
When people first hear about an inverted index, they typically envision a straightforward map: terms as keys and document lists as values. That picture works fine at a high level, but it misses the real story.
Lucene's inverted index is far more sophisticated. It's built to handle not only exact lookups but also range queries, wildcards, and fuzzy matches, all while staying fast at scale. The secret behind this efficiency is a data structure called a finite state transducer (FST).
In this article, we'll unpack how Lucene goes beyond a "map" and how the FST plays a central role in making advanced queries possible.
What if the inverted index was just a map?
Let's start with a thought experiment. Suppose Lucene's inverted index really was just a plain map.
- For exact lookups like
"apple"or"banana", it would work fine. - But what about a prefix query like
"hello*"? Since the map isn't ordered, Lucene would need to scan every key to find matches which is far too slow for large indexes. - Similarly, a range query such as
["apple", "banana"]would require a full table scan, again impractical at scale.
In short, a simple map would fall apart in real-world search workloads. Lucene needs something better.
Enter finite state transducers (FSTs)
Lucene addresses this problem with FSTs, which can be thought of as a prefix-compressed trie with additional metadata. Refer to the image given below to get a high-level idea of how it looks.
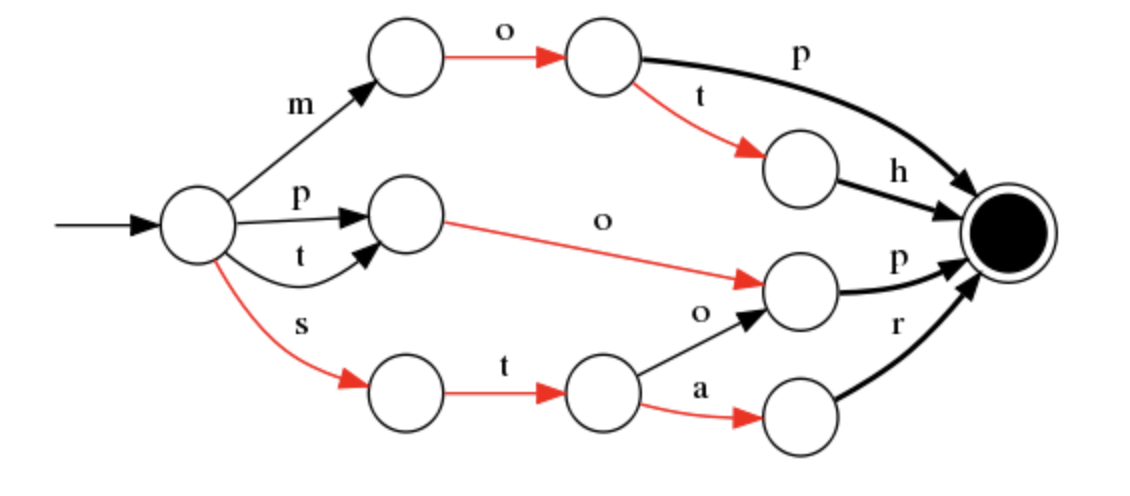
Here's how it works in practice:
Terms dictionary (.tim)
Stores all terms in a sorted, block-wise fashion. Each entry points to its postings list (the actual document references).
Term index (.tip)
An FST is built for each field. It maps prefixes to blocks in the terms dictionary.
Metadata (.tmd)
Stores term statistics (like frequency, min term, max term) and, importantly, pointers to the FSTs.
When Lucene searches for a term, it jumps into the correct part of the FST using the metadata file, finds the right block in the terms dictionary, and then retrieves postings from there.
Because these structures are compressed, Lucene can memory-map them efficiently, keeping searches fast even for huge indexes.
Why FSTs matter for queries
Exact term queries
A lookup like "apple" is straightforward. The FST quickly points to the right block, and Lucene retrieves the postings.
Range queries
For queries like ["apple", "banana"], Lucene uses the fact that terms are stored in sorted order. It finds the start term via the FST, then scans forward in the dictionary until the end term.
Fuzzy queries
A fuzzy query such as "cat~1" (terms within one edit distance of "cat") is more complex. Lucene builds an automaton representing valid edits, then intersects it with the FST to find matching terms efficiently.
(Note: Many readers confuse this with brute-force scanning. The automaton+FST approach is why Lucene's fuzzy queries are orders of magnitude faster than naïve implementations. Read more about it here)
Wildcard queries
Prefix wildcards like "hello*" are handled naturally by traversing the FST from the "hello" node and enumerating all downstream terms.
However, leading wildcards such as "*hello" are problematic. Since FSTs are prefix-based, Lucene cannot optimize these, and they may require scanning large parts of the terms dictionary.
Ending notes
In this blog, we read about the internals of Lucene's inverted index that are often misunderstood in theory.
Knowing internals could help us optimize our workloads too.
I hope you learned something new today.
Don't forget to follow me for more deep dives like this.
References:
https://blog.mikemccandless.com/2010/12/using-finite-state-transducers-in.html
https://blog.mikemccandless.com/2011/01/finite-state-transducers-part-2.html
https://blog.mikemccandless.com/2013/06/build-your-own-finite-state-transducer.html
https://blog.mikemccandless.com/2013/09/lucene-now-has-in-memory-terms.html
https://blog.mikemccandless.com/2011/03/lucenes-fuzzyquery-is-100-times-faster.html