Why Lucene Never Stores Document IDs the Way You Think
5 min read
I was recently going through Lucene’s internals, and one detail caught my attention: posting lists aren’t stored as plain arrays. Instead, Lucene uses delta encoding, which is a compression technique that drastically reduces space without losing information.
This optimization might seem small, but at a search engine scale, where millions of terms map to billions of postings, it makes a massive difference.
And the best part? The same principle is useful in many other systems too.
Let’s break it down step by step
Inverted index (a quick refresher)
At the core of Lucene is the inverted index. Think of it as a giant lookup table:
- On the left: terms (words or tokens).
- On the right: postings (information about which documents contain the term).
For example, given two documents:
{ "text": "hello world" } // Doc 1
{ "text": "hello lucene" } // Doc 2
The inverted index would look like:
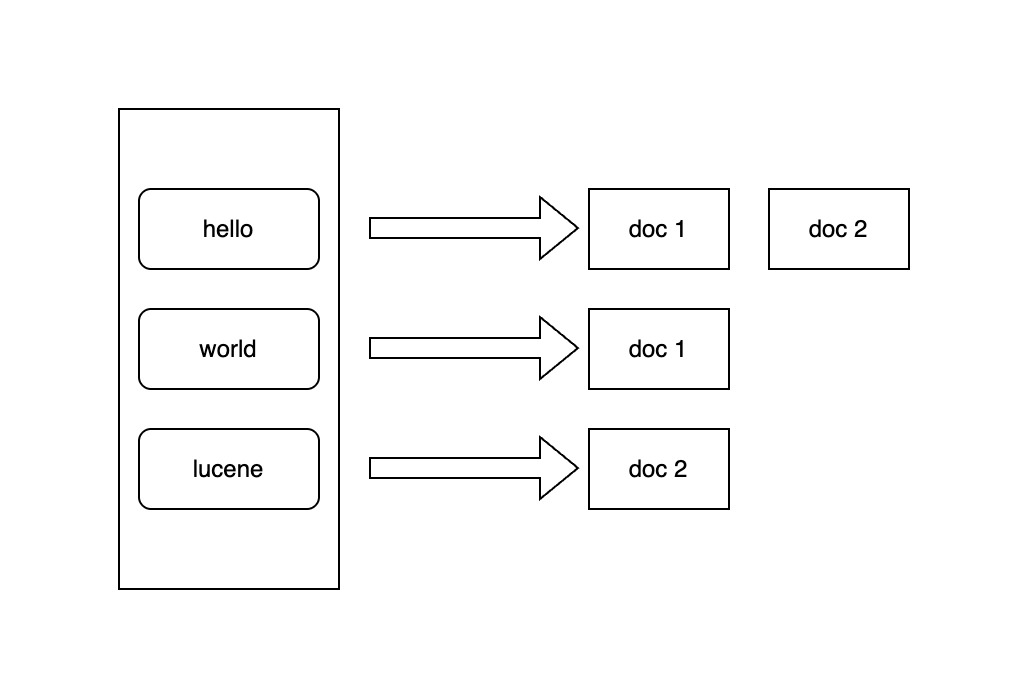
Each list of document IDs is called a postings list. In this toy example, lists are tiny. But in a large corpus, common terms might appear in millions of documents, so the postings list can become enormous, and hence compressing them is critical.
Let’s see in the next section how Lucene actually compresses the postings list.
Delta encoding (the key idea)
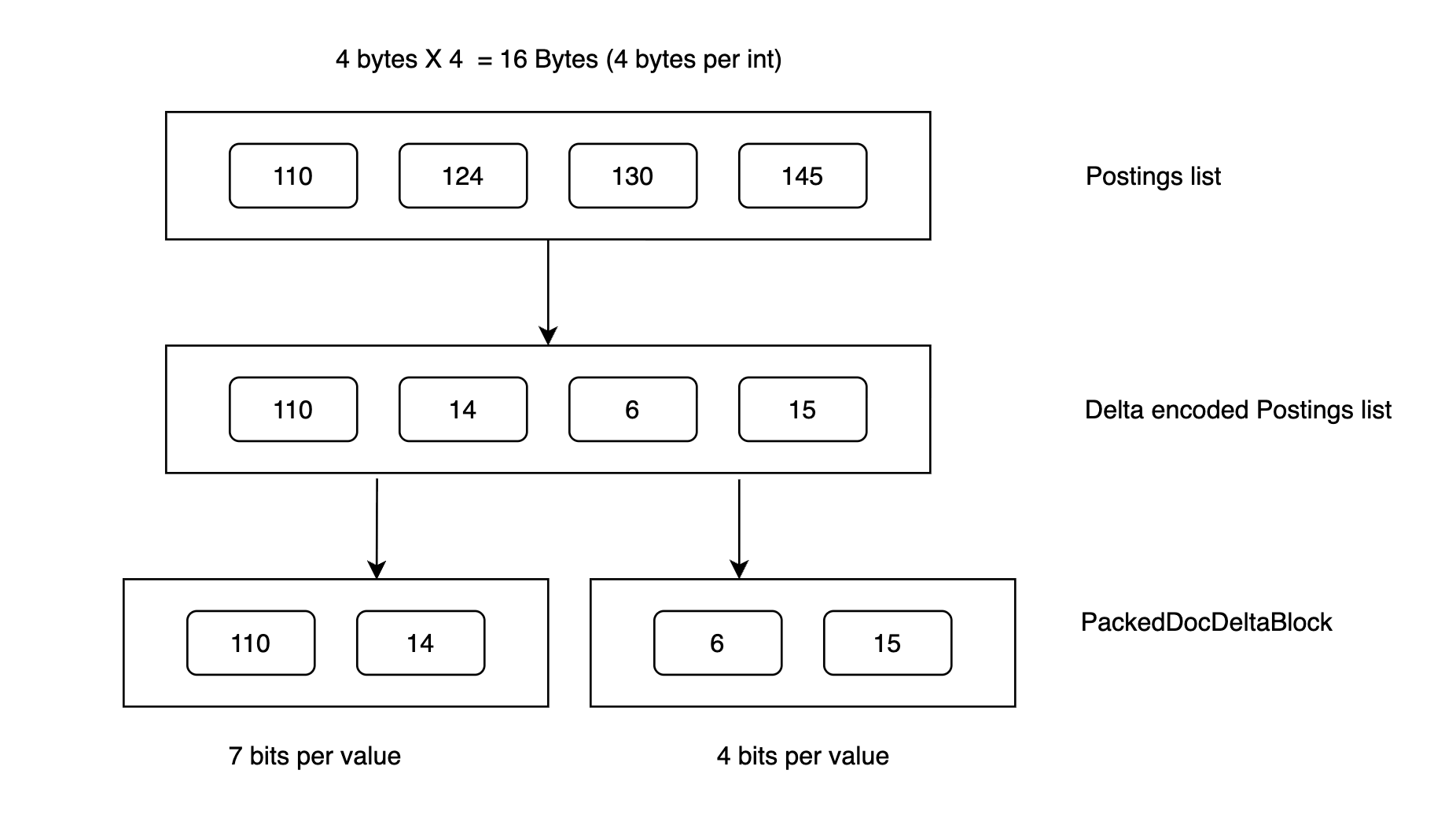
Instead of storing raw document IDs, Lucene stores gaps (deltas) between them.
Original list
Take this example postings list:
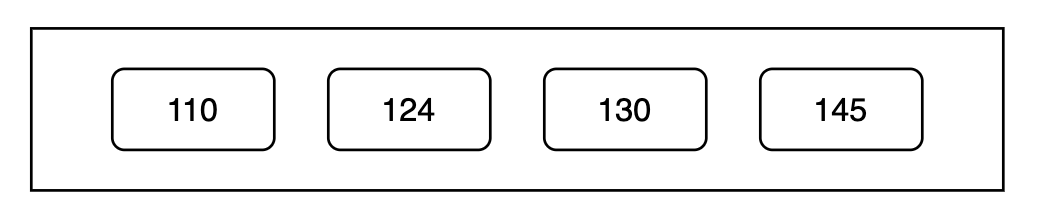
Here, the size of an int (in Java) is 4 bytes, and for 4 values, we will need 16 bytes.
Delta encoded list
We take the first element as a reference point, and for every following element, we record the difference from the one before it. Applying this to our example gives us something like:
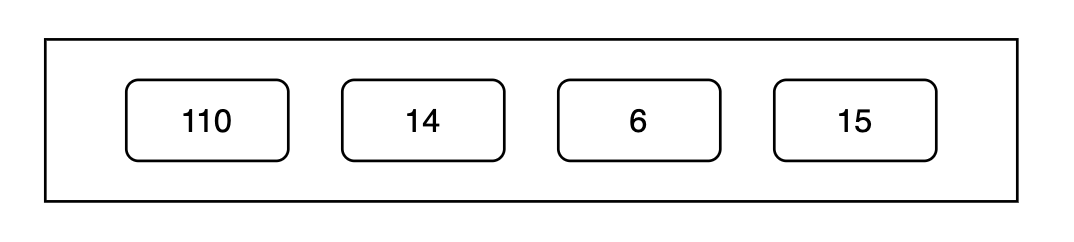
Blocking for efficiency
Lucene doesn’t compress the entire list at once. Instead, it splits it into fixed-size blocks (called PackedDocDeltaBlock in Lucene). In this example, let’s consider the block size is 2 values per block. This will look like:
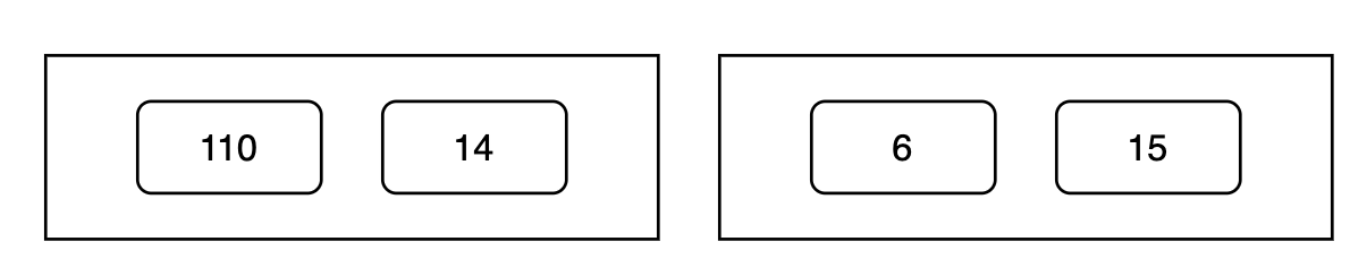
Now, for each block, Lucene:
- Finds the maximum value.
- Determines the minimum number of bits needed.
- Stores the values tightly packed together using just those bits.
The block header stores metadata (such as the number of bits required per number in a single byte) so that the decoder can reconstruct the list later. You could refer to the image given below to understand this better:
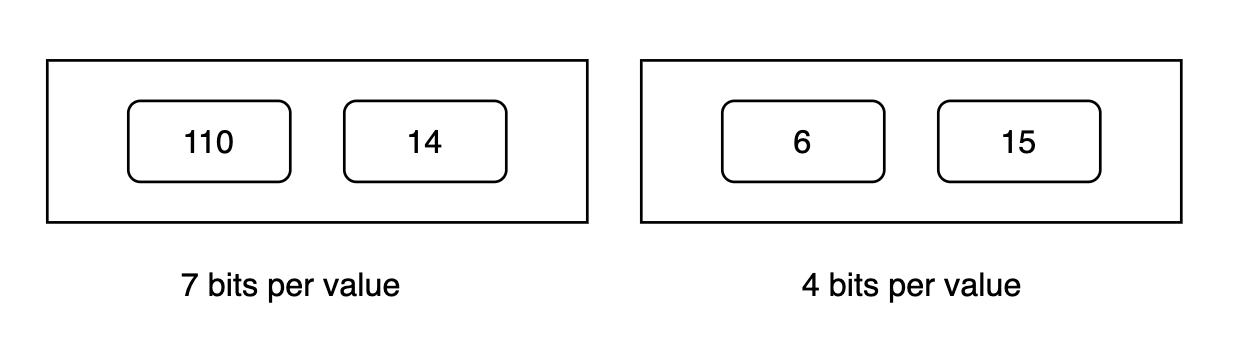
This reduces the original 16 bytes to around 5 bytes (7 bits * 2 + 4 bits * 2 = 22 bits = 2.75 bytes + 1 byte in each block for the header = 5 bytes) in this example, which is a huge saving at scale.
The final step is storing values in a packed integer structure. This means values are laid out directly at the bit level, back to back, without wasting unused bits.
For instance, two numbers:
- 8 → needs 4 bits
- 16 → needs 5 bits
Together, they take just 9 bits. Instead of wasting a whole 32-bit integer for each, Lucene packs them efficiently into a continuous bit array (within a single int).
This technique is widely used beyond Lucene too. Roaring Bitmaps or Java’s Bitset are two very good examples of the same, which I’ve covered in earlier posts. Read these articles to get a better understanding of bit packing.
The entire process is described in the following diagram for a quick overview:
Ending notes
In this article, we saw how Lucene compresses data to prevent wastage of space, and it’s a reminder of the engineering brilliance behind search libraries: powerful abstractions on the outside, and incredibly efficient low-level optimizations underneath.
Thank you for reading. I hope you learned something new today.
References:
https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps
https://lucene.apache.org/core/8_8_1/core/org/apache/lucene/codecs/lucene84/Lucene84PostingsFormat.html
Happy coding!