The RAM You Didn't Know You Were Using: Page Cache Explained
5 min read
The page cache is a performance optimization used by modern operating systems to speed up disk I/O. It acts as a buffer between your applications and the storage device by caching frequently accessed disk pages in RAM. This reduces latency and improves throughput for both reads and writes, often without the application even knowing.
How does it work?
Let’s walk through what happens behind the scenes during read and write operations when the page cache is involved.
Read path
When you read a file from disk, the OS first determines which disk pages are needed. It then checks whether those pages are already in the page cache:
- If found in the page cache, the data is returned immediately from RAM.
- If not found, the OS reads the data from disk and stores it in the page cache for future access.
This behavior is similar to a read-through cache, where data is automatically loaded into the cache upon a cache miss.
Write path
When writing data to a file, the data is initially written to the page cache, not to disk directly. These pages are marked as dirty, meaning they've been modified in memory but not yet persisted.
The OS then uses background threads to flush these dirty pages to disk asynchronously. This makes the page cache behave like a write-back cache.
Write-back caching helps group small writes and reduces disk I/O, but introduces a trade-off that recent writes may be lost if the system crashes before the flush.
Can you disable the page cache?
You generally cannot disable the page cache globally via standard operating system settings. However, the most common way to bypass it at the application level is by using the O_DIRECT flag when opening a file.
This tells the kernel: "Do not cache this read or write. Operate directly on the disk."
But why use O_DIRECT?
There are several reasons why an application might choose to bypass the page cache using O_DIRECT, and these reasons can differ for read and write operations.
For Writes:
- Prevent double-buffering (data in user buffer and OS cache).
- Avoid data loss risks from delayed flushes.
For Reads:
- Avoid polluting the cache with one-time large reads (e.g., backups, media processing).
- Rely on your application-level caching logic.
Additionally, if a system needs to benchmark raw disk performance, whether for reads or writes, it will often bypass the page cache in both cases to avoid memory-based optimizations that could distort the results.
Seeing page cache in action (macOS example)
Here's a simple demo you can try on macOS to observe the page cache behavior:
Assume you have a file named largefile (~4 GB in this example):
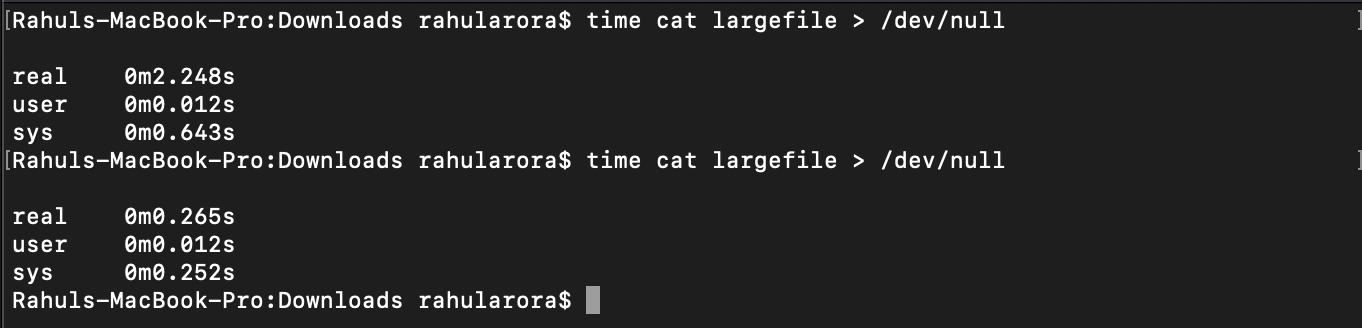
Step 1: First read (cold cache)
This takes around 2.2 seconds as the data is read from disk.

Step 2: Second read (warm cache)
Now it took only 265 ms, which is much faster than the last time, because it's served from RAM.
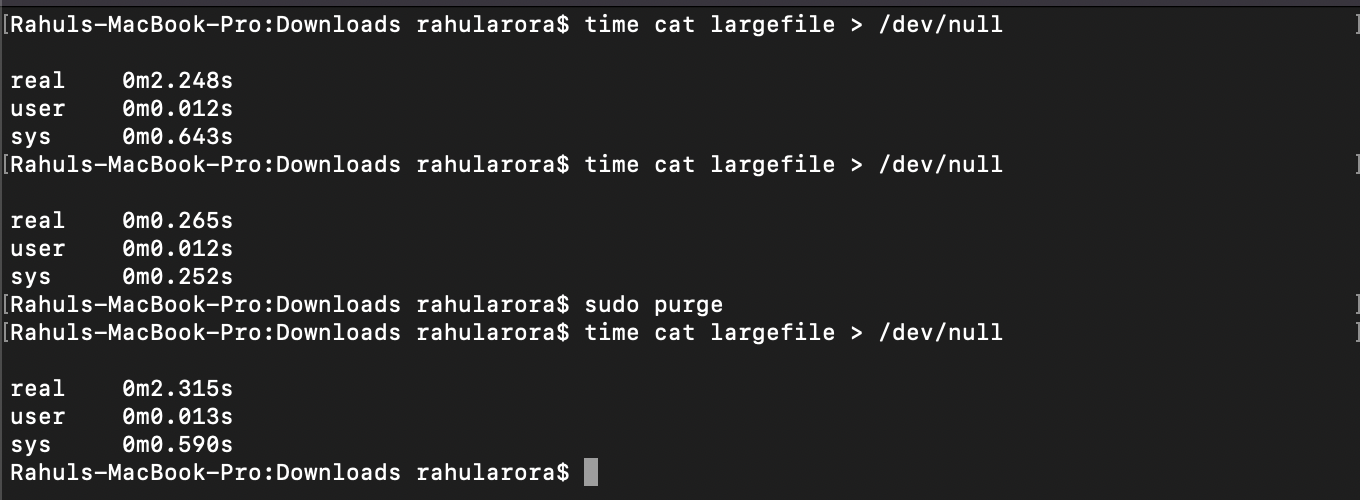
Step 3: Clear page cache and read again (cold cache again)
You'll notice the read time is again close to the original cold read.
Some real-world systems that rely on page cache
Several major systems rely on the OS page cache for performance and simplicity.
Kafka
Kafka depends heavily on the page cache for log I/O. It reads and writes segment files directly through the filesystem and relies on the OS to cache frequently accessed log entries.
Google File System (GFS)
In GFS, chunkservers store file chunks but do not maintain their own in-memory cache. Instead, they rely on the page cache to retain recently accessed data, offloading the caching responsibility to the OS.
RocksDB
RocksDB is a popular key-value store built on a log-structured merge tree (LSM). It stores data in immutable SSTables on disk, which makes them ideal candidates for page caching. Random reads are much faster when SST files are already cached in memory.
Ending notes
The page cache is one of those hidden performance boosts most applications unknowingly benefit from. While it's incredibly useful in most cases, understanding how it works and how to bypass it when needed gives you a powerful tool for optimizing performance.
Hope you learned something new today.
Thank you for reading. Happy coding!