Understand the Inner Mechanics of a Phonetic Spell-Check Algorithm
6 min read
Spell-check is one of the most crucial parts of any search system, playing an important role in correcting common typos and enhancing the relevance of search results.
There could be a lot of reasons why a user may type a wrong spelling. This includes typing errors on the keyboard (like 'the' and 'thw'), phonetic errors (like 'wiskee' and 'whisky'), wrongly merged words (like 'youare' and 'you are'), and many more. To address these issues, search systems typically employ a combination of algorithms that target different problems, resulting in the best possible outcomes.
In this article though, we are just going to focus on a phonetic spell-check algorithm called Soundex. So without further ado, let's begin.
How do phonetic spell check algorithms work?
The basis of phonetic spell-check algorithms lies in the phonetic representation of words. These algorithms aim to map words with similar pronunciations or phonetic characteristics to the same or similar representations. By doing so, they enable the identification and correction of spelling mistakes based on their phonetic similarity rather than their exact textual form. But how is this achieved?
The crucial part of the entire process is to generate a phonetic hash of a word and then compare it with the rest of them. While different algorithms produce varied hashes, Soundex, for instance, generates a four-letter code.
Follow the algorithm given below to understand how a phonetic hash of a word is generated using Soundex.

The Soundex algorithm, as you can observe, is remarkably simple yet capable of handling challenging cases. To illustrate its effectiveness, let's examine an example involving the brand name Skullcandy and its various phonetic errors. Given below is an image for the same.
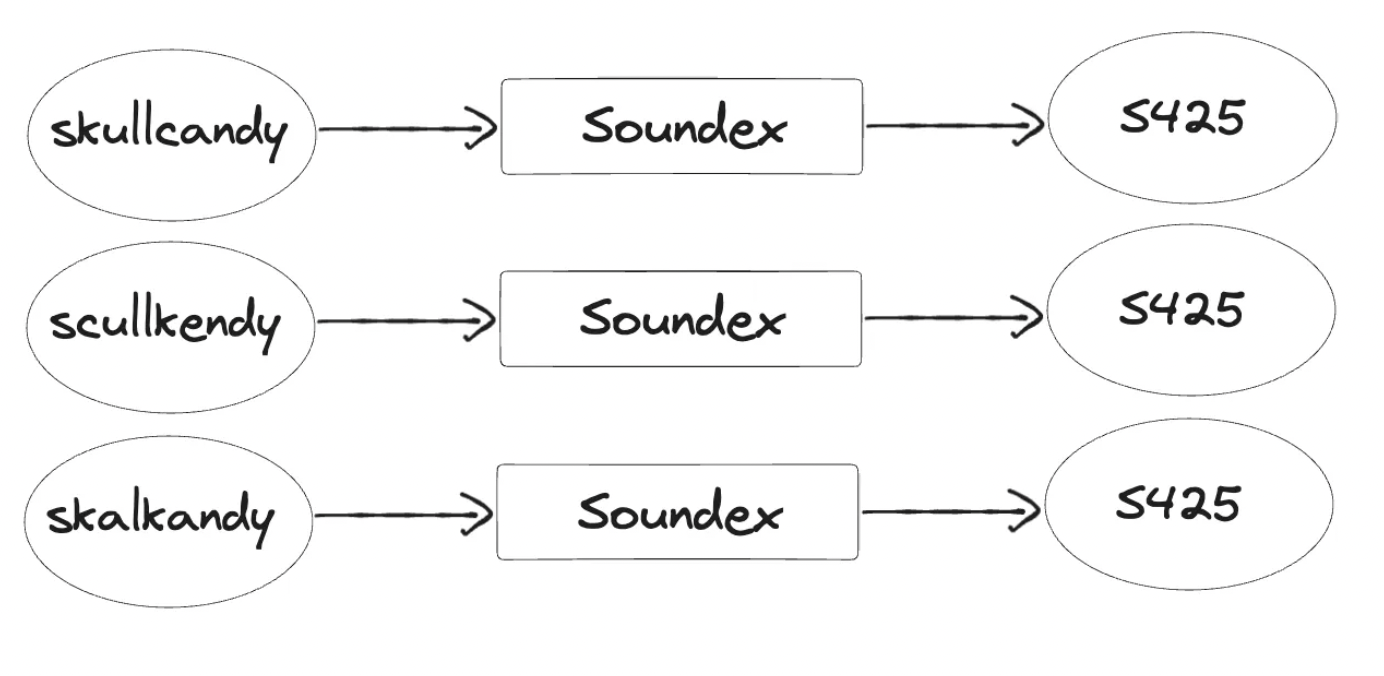
In this example, only one spelling (skullcandy) was correct and the other two (scullkendy and skalkandy) were similar sounding but not correct. Interestingly, despite their differences, all three spellings share the same phonetic hash (S425) and hence they will be considered as the same word.
You can use this online tool if you want to play around with the algorithm.
How does it all fit in?
This section will give you a brief idea of how any spell-check algorithm is used in a real-world search system.
When a user submits a query, it is initially divided into individual tokens, typically based on whitespace. For instance, tokenizing the phrase "Livais jeens" would yield a token list containing ["Livais", "jeens"].
Following tokenization, we compute the phonetic hash for each token. Using Soundex, for example, the resulting hashes would be ["L120", "J520"].
Now comes a slightly more complex step. For each token, we search an inverted index to retrieve a list of words that share the same phonetic hash. This step is precomputed to avoid computational overhead at runtime. It's worth noting that this phase, known as candidate generation, can yield multiple candidates for each hash token.
The real challenge lies in ranking these candidates and selecting the most appropriate one. Typically, this ranking process, referred to as candidate selection, is facilitated by another component of the search system.
Going into the ranking part of it would be out of scope for this article. However, as a general overview, a basic approach involves having a list of all possible words in a dictionary, along with their respective frequencies stored in a database. This data can assist in sorting the candidate word list based on occurrence frequency, often producing satisfactory results for many cases.
And that's it, if everything works fine then you would most likely get "Levis jeans" as the corrected query for the "Livais jeens" search phrase.
Limitations
As we have seen in the previous sections, Soundex is a very simple yet powerful algorithm for phonetic spell correction. Still, it suffers from some limitations. Some of them are listed below:
- It is primarily tailored to the English language. Adjusting it to align with the phonetic rules and characteristics of the target language could take significant effort and iterations.
- Because of the first letter retention, some similar-sounding names can have different phonetic hashes. For example "Clara as C460" and "Klara as K460".
- Soundex codes are fixed in length and may not adequately represent longer or shorter names. Longer names may be truncated, potentially leading to loss of information, while shorter names may not provide enough phonetic detail.
Ending notes
Building a spell-check system takes a lot more than what was explained in this article. But, understanding the fundamentals of it can help you to independently explore the world of Information retrieval systems. Given below are some resources to help you go in-depth of it.
- https://assets.amazon.science/dc/d6/658d7aca45f38b6557458c457fa3/spelling-correction-using-phonetics-in-ecommerce-search.pdf
- https://discovery.ucl.ac.uk/id/eprint/10065716/1/DEXA-2014-FPSS.pdf
- https://nlp.stanford.edu/IR-book/html/htmledition/phonetic-correction-1.html
- https://www.openbookproject.net/py4fun/soundex/soundex.html
Hope you learned something new today.
Thank you for reading. Happy coding!