Why InnoDB Secondary Indexes Use the Primary Key as an Indirection?
7 min read
While diving into Database Internals, I stumbled upon an interesting design concept: using the primary key as an indirection for secondary indexes. Instead of pointing directly to row data on disk, a secondary index can point to the primary index, which then leads to the actual row.
This sparked my curiosity, and I wondered why add this extra hop? What are the trade-offs? To answer that, I decided to explore how MySQL's InnoDB engine handles this and what it means for query performance, storage layout, and index tuning.
Turns out, this indirection brings both clever optimizations and subtle pitfalls.
Let's unpack it.
How InnoDB organizes data: The primary index
In InnoDB, every table is stored as a clustered B+ tree, ordered by its primary key. This means:
- The B+ tree is sorted by the primary key column(s)
- Each leaf node contains the full row data
- There's no separate heap. The table is the index
To fetch a row using the primary key, InnoDB walks the tree until it reaches the appropriate leaf node and retrieves the row from there.
What about secondary indexes?
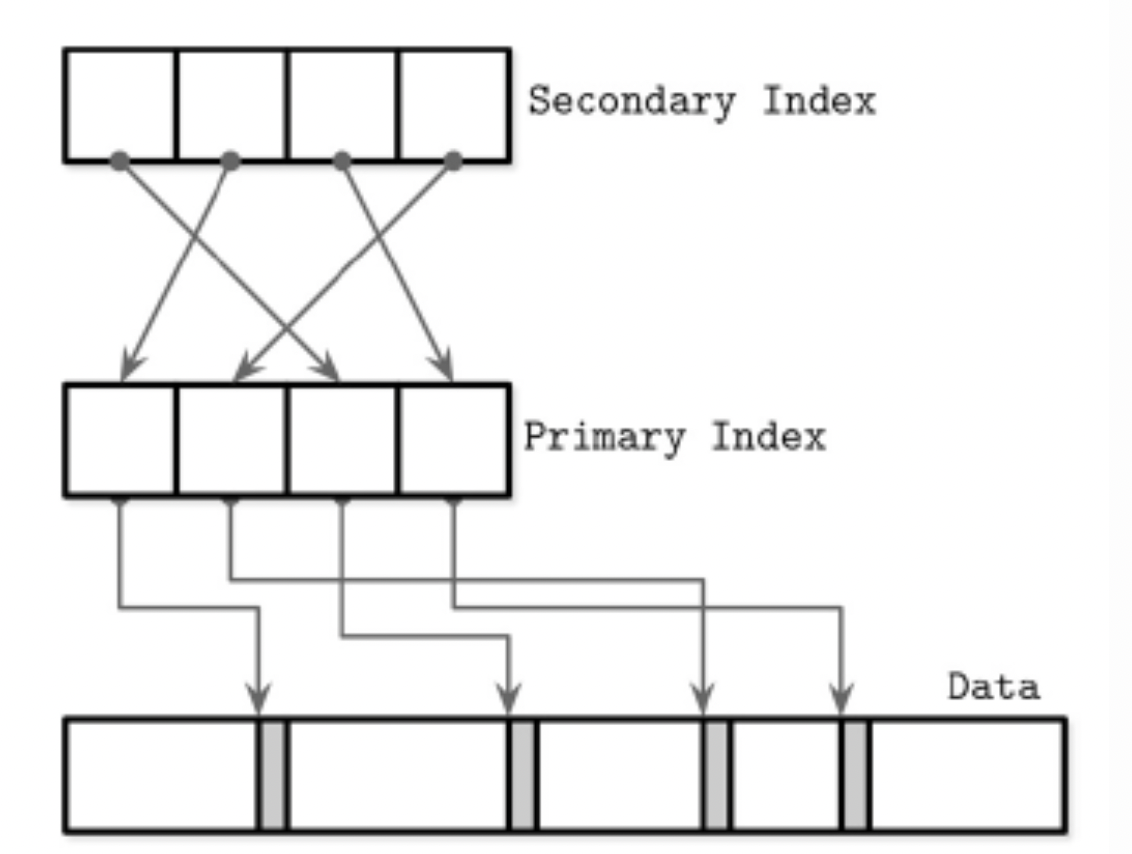
Secondary indexes are also B+ trees, but ordered by a different column (or columns). However, instead of pointing directly to disk locations, the leaf nodes in secondary indexes store the primary key of the row.
This is crucial: secondary indexes never contain the full row by default. Instead, InnoDB does the following:
- Traverse the secondary index to find the matching entry.
- Use the stored primary key to look up the row in the primary index.
- Retrieve the full row from there.
Let's take an example:
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
age INT,
email VARCHAR(100)
);
CREATE INDEX idx_age ON users(age);
Now, if you query:
SELECT email FROM users WHERE age = 30;
Then InnoDB does the following things:
- Walks
idx_age(secondary index) to find entries withage = 30 - For each match, use the stored
idto perform a second lookup in the primary index - Finally, fetches the full row to extract
email
That's a double read. One from idx_age, and one from the primary index.
The following diagram is borrowed from the book itself. It will help you to visualize this better.
What are the pros and cons?
Using the primary key as an indirection in secondary indexes is a trade-off. Here are the key advantages and disadvantages to consider.
Pros
- Row updates don't require modifying secondary index entries unless the PK changes. This is one of the major advantages of using this approach, especially on write-heavy systems.
- No redundancy of row data across indexes. Only the primary index stores full rows, reducing duplication.
Cons
- Often, rows are not clustered by the secondary index order, hence PK lookups become random disk reads. This is especially more prominent when there are range scans on the secondary index.
- In a range scan, InnoDB walks the secondary index, and for each match, dereferences the primary index, which causes double I/O.
Common index optimizations to improve read performance
Covering indexes
If your query can be answered entirely using the secondary index (i.e., all required columns are present in the index), InnoDB doesn't have to touch the primary index at all. Imagine you have a table like this:
CREATE TABLE users (
id INT PRIMARY KEY,
age INT,
name VARCHAR(100),
email VARCHAR(100)
);
With an index like below:
CREATE INDEX idx_age ON users(age);
Now, if you run a query like below:
SELECT name FROM users WHERE age = 30;
This query requires accessing the primary index, because name is not part of the secondary index.
On the other hand, if you define your index like below:
CREATE INDEX idx_age_name ON users(age, name);
Now the query becomes a covering query. Everything needed (age, name) is available in the index itself. Only one tree is touched.
INCLUDE columns (In MySQL 8.0+)
What if you want to include extra columns in the index without affecting the sort order?
Use INCLUDE:
CREATE INDEX idx_age_include_email ON users(age) INCLUDE (email);
- The index is still sorted by
age emailis included only in the leaf nodes- Useful for filtering on age while returning
email-- No need to go to the primary index
This helps keep the internal B+ tree structure compact while still enabling covering queries.
Tuning buffer pool
A secondary index lookup in InnoDB is often said to require two I/Os per row: one for the secondary index and one for the primary index. But this is an oversimplification. Since both indexes are B+ trees, each lookup may involve multiple I/Os to traverse internal and leaf pages, especially if they're not cached.
These disk reads can be significantly reduced if the InnoDB buffer pool is large enough to hold a good portion of your frequently accessed index pages and row data.
Ending notes
Understanding how InnoDB uses the primary key as an indirection in secondary indexes helps demystify some of the performance quirks you might observe in real-world queries.
Behind the scenes, this indirection adds flexibility and write efficiency, but it also introduces an extra hop in the read path. Knowing how this works under the hood can help you design better indexes and write more efficient SQL.
I regularly read a wide range of technical books and share my learnings here, whether it's database internals, system design, or just clever engineering ideas. Feel free to explore the rest of the blogs if that sounds interesting to you.
References:
https://en.wikipedia.org/wiki/B%2B_tree
https://dev.mysql.com/doc/refman/8.4/en/innodb-index-types.html
Thank you for reading.
Happy coding!