Kafka: a Distributed Messaging System for Log Processing
7 min read
These are just high-level notes to give you a quick overview. For the full details, read the complete research paper here.
Introduction
Kafka is a distributed messaging system, designed with inspiration from traditional messaging platforms. However, it introduces a few unconventional design choices that make it exceptionally efficient.
Kafka is well-suited for both online and offline data consumption. At the time this research paper was published, LinkedIn had already been using Kafka in production for about six months.
Related work
Traditional messaging systems have existed for a long time but they are not quite suitable for log processing.
- They provide reliable delivery semantics but they are not suitable for systems where losing some messages (like page views) is acceptable.
- They also not focus on throughput as the core design goal. Example, JMS has no API to allow the producer to batch multiple messages into a single request. This means each message will incur a complete TCP/IP roundtrip.
- They are weak in distributed support. There is no easy way to partition the messages and store them in different machines.
- They assume near immediate consumption of messages. Their performance starts to degrade as the messages grow.
Other systems that exist (like Facebook's Scribe or Yahoo's data highway) are mostly designed for handling offline log consumption. Additionally, most of them are push based.
Kafka architecture and design principles
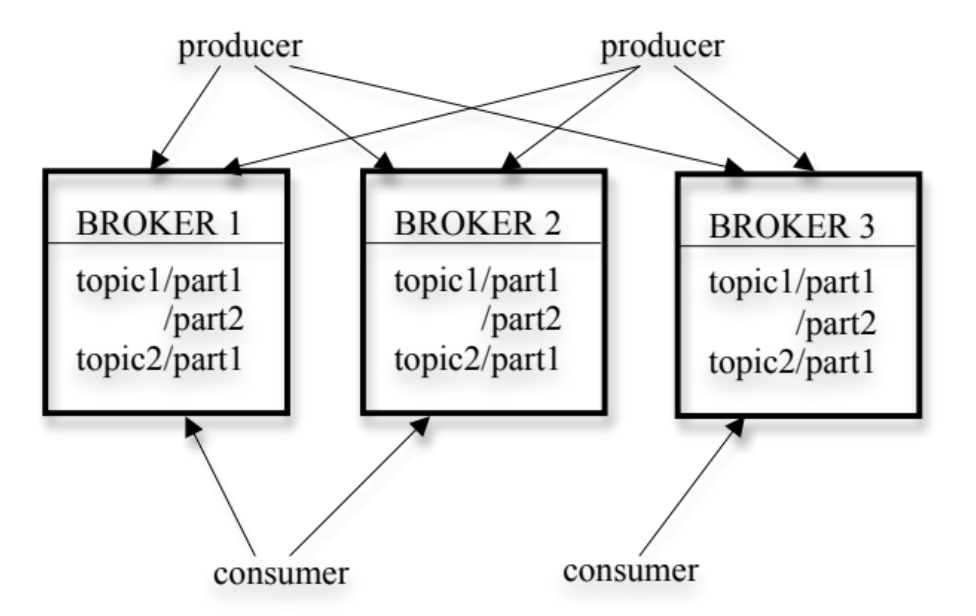
A stream of messages of a particular type is defined by a topic (example a topic for just user sign-ups). A producer can publish messages to a topic. The published messages are then stored at a set of servers called brokers. A consumer can subscribe to one or more topics from the brokers, and consume the subscribed messages by pulling data from the brokers.
Messages can be encoded using any serialisation method. For efficiency, the producer can send multiple messages in one request.
Messages are sent to random partitions or to a specific partition based on a key. The key is used to ensure that messages with the same key are always sent to the same partition, which is important for maintaining order for those messages.
To consume messages, consumers are grouped into what’s called a consumer group. Each consumer in the group reads from a subset of the topic's partitions, allowing parallel processing. Multiple consumer groups can independently consume the same topic—for example, both a search ingestion system and an ad analytics system might consume the same page view events.
Each topic is split into multiple partitions, which helps distribute load and increase parallelism. These partitions are also replicated across different brokers to ensure fault tolerance and high availability.
Refer to the image below for a visual representation of the Kafka architecture:
Efficiency on a single partition
Simple storage
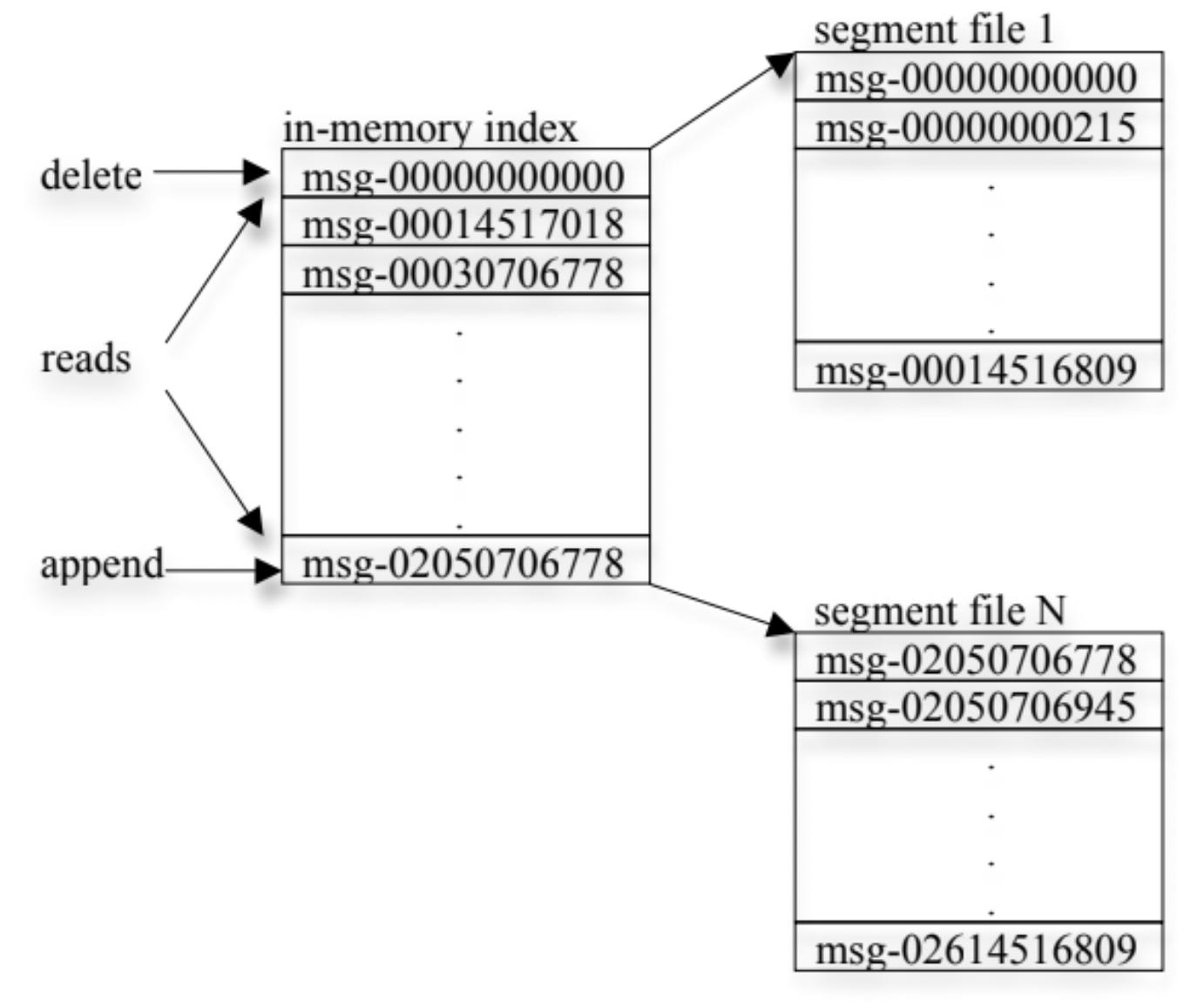
Each partition is divided into multiple files of almost the same size. New messages are appended to the current file. These messages are buffered in memory and are flushed in batches for better efficiency.
Unlike typical messaging systems, Kafka messages don’t have explicit IDs. Instead, each message is identified by its logical offset in the log, avoiding the overhead of random-access indexes. These offsets increase but aren’t necessarily consecutive. Each new offset is computed by adding the current message’s length to its offset.
Consumers read messages sequentially from a partition. Acknowledging an offset implies all prior messages have been received. Consumers issue asynchronous pull requests with a starting offset and byte limit. Brokers maintain an in-memory list of offsets (e.g., segment starts) to locate the correct file and return data. After consuming a message, the consumer calculates the next offset and uses it in the subsequent pull request. Image given below illustrates the log layout and offset index.
Efficient transfer
Producers can send multiple messages in a single request. Consumers can also read multiple messages in a single fetch request.
No external cache is used to store the messages. Kafka relies on the OS page cache. This has the main advantage of avoiding double-buffering. This has the additional benefit of retaining warm cache even when a broker process is restarted. This also avoids the garbage collection cost.
Kafka also uses the concept of zero copy. Sending bytes from a local file to a remote socket typically involves four data copies and two system calls: reading from disk to the page cache, copying to an app buffer, then to a kernel buffer, and finally sending to the socket. Linux's sendfile API reduces this overhead by eliminating two copies and one system call, enabling direct transfer from file to socket.
Stateless broker
Unlike most messaging systems, Kafka lets consumers track their own consumption progress instead of relying on the broker. This design simplifies the broker and reduces its overhead.
Distributed coordination
Each partition of a topic is the smallest unit of parallelism. This means that at any given time, all messages from one partition are consumed only by a single consumer within each consumer group.
There is no master node. Consumers coordinate among themselves in a decentralized fashion. This is facilitated by a highly available consensus service called Zookeeper.
Kafka uses Zookeeper for the following tasks:
- Detecting the addition and the removal of brokers and consumers.
- Triggering a re-balance process in each consumer when the above events happen.
- Maintaining the consumption relationship and keeping track of the consumed offset of each partition.
Delivery guarantees
In general, Kafka only supports at-least once delivery. For exactly-once delivery, applications are expected to maintain their own de-duplication logic.
The messages delivered from one partition to a consumer are always in-order. However, messages from different partitions may not be in order.
This summary provides a brief overview of the Kafka research paper. Note that the paper is dated, and many aspects of Kafka have evolved since its publication. For up-to-date information, consult the official Kafka documentation.
For a deeper understanding, you can read the full paper here.